



¿Te suena familiar? Tu organización ha invertido millones en plataformas, arquitecturas y especialistas en datos… pero los equipos siguen luchando por acceder a datos confiables, en tiempo, y con contexto.
Si esto te resulta conocido, no estás solo. A medida que las organizaciones escalan sus estrategias de datos, muchas descubren que el enfoque tradicional de arquitectura centralizada ya no es suficiente. Aquí es donde entra en juego el ecosistema Data Mesh.
¿Qué es un Ecosistema Data Mesh?
Data Mesh no es una herramienta ni una tecnología. Es un paradigma de arquitectura de datos descentralizado, que propone un cambio de mentalidad:
Pasamos de ver los datos como un subproducto de los sistemas, a gestionarlos como productos digitales con dueños claros, reglas de gobernanza y SLA definidos.
Un ecosistema Data Mesh es el entorno completo (tecnológico, organizacional y operativo) que permite implementar este modelo. Abarca desde las plataformas de datos, pipelines, y políticas de gobierno, hasta los equipos y prácticas que lo sostienen.
¿Por qué las arquitecturas tradicionales están fallando?
En los modelos centralizados como los data lakes monolíticos o los data warehouses tradicionales, un único equipo de datos se encarga de todo: ingesta, modelado, calidad y entrega. A medida que la organización crece, este equipo se convierte en un cuello de botella.
Esto produce:
- Retrasos en la entrega de datos
- Falta de contexto en los sets de datos
- Pérdida de confianza en los resultados
El Data Mesh propone descentralizar, asignando la responsabilidad del ciclo de vida de los datos a los equipos de negocio que los generan. Pero descentralizar no significa caos: requiere una infraestructura y cultura sólida para que funcione.
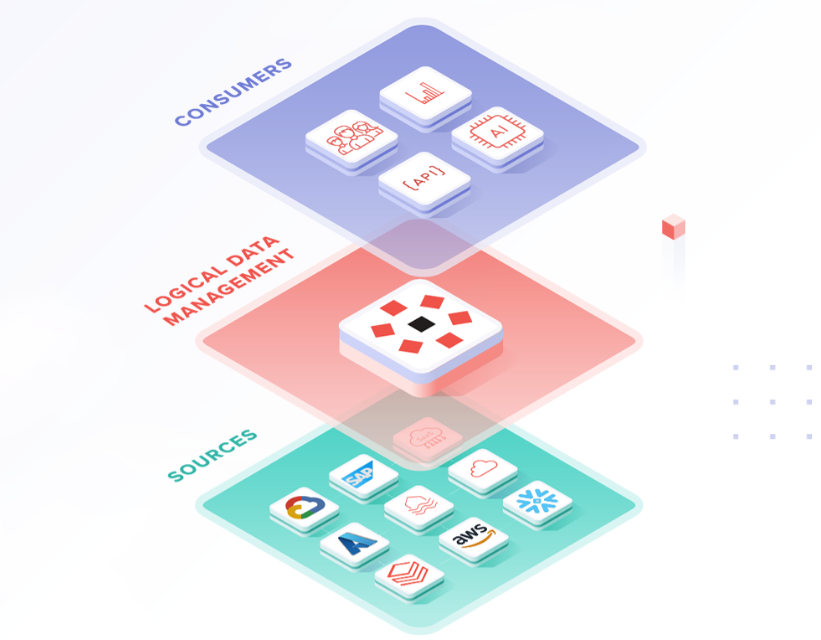
Componentes clave del ecosistema Data Mesh
1. Dominios de datos
Los datos se organizan según áreas de negocio (finanzas, operaciones, marketing…). Cada dominio es responsable de sus propios data products, gestionando calidad, documentación y gobernanza.
2. Infraestructura de autoservicio
Es la capa tecnológica que permite a los equipos crear, desplegar y consumir data products sin depender del equipo central. Incluye:
- Plataformas de orquestación (como Databricks, Airflow o dbt)
- Infraestructura cloud (como AWS, Azure o GCP)
- Herramientas de catálogo y observabilidad (como DataHub)
3. Gobernanza federada
No es ausencia de reglas, sino una gobernanza distribuida pero coordinada. Se definen políticas globales (seguridad, privacidad, trazabilidad), pero su implementación se adapta a cada dominio.
4. Cultura orientada al producto
Cada dominio trata sus datos como productos: con usuarios objetivos, KPIs, documentación técnica y mantenimiento continuo. Esto implica métricas de confiabilidad, discoverability y reusabilidad.
Beneficios tangibles de adoptar un ecosistema Data Mesh
Empresas que adoptan este enfoque han logrado:
✅ Reducir el time-to-data de semanas a horas
✅ Mejorar la calidad y trazabilidad de los datos
✅ Aumentar el ownership y la colaboración entre negocio y tecnología
✅ Escalar operaciones de datos sin duplicar recursos
Un ejemplo concreto: una telco latinoamericana redujo en 60% los ciclos de desarrollo de dashboards analíticos luego de descentralizar la creación de data products por dominio.
El Data Mesh no reemplaza tus tecnologías actuales, las potencia. No se trata de tener más herramientas, sino de repensar cómo las personas, procesos y plataformas trabajan juntas para escalar el valor de los datos.
El camino no es inmediato, pero quienes lo han transitado coinciden: construir un ecosistema Data Mesh es una inversión estratégica para dejar atrás el caos de los datos… y pasar a una era donde los datos realmente están al servicio del negocio.



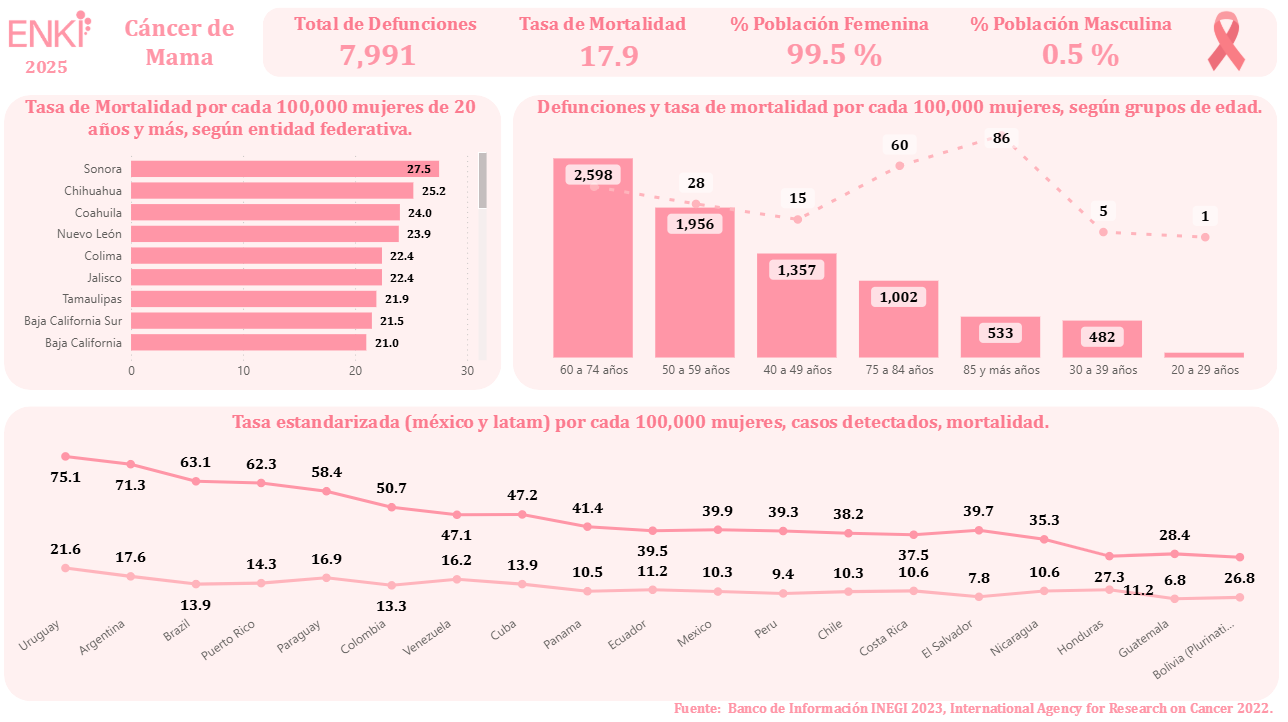
































© 2026 - Todos los derechos reservados ENKI. Ciudad de México.
