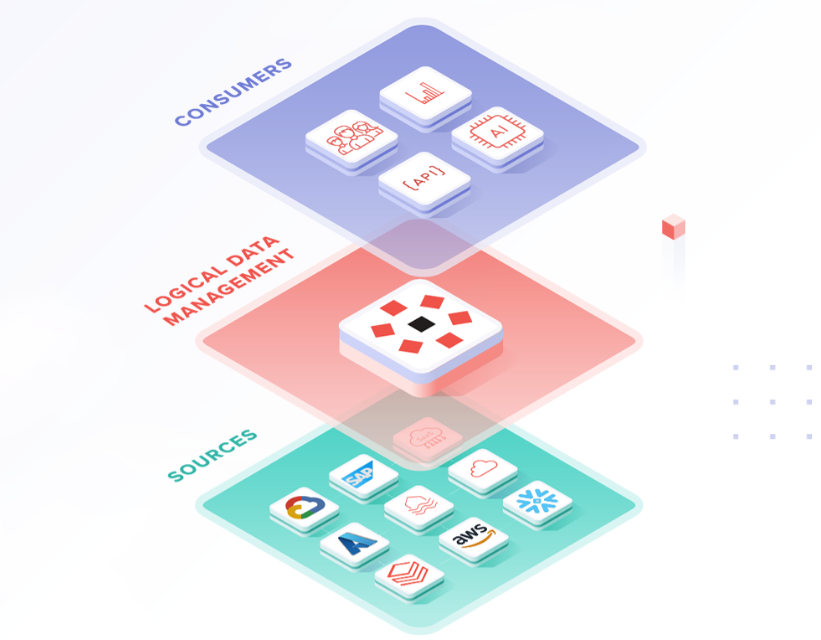
Enterprise data management has evolved significantly over the past decade. Where we used to talk about centralized data warehouses, organizations now need platforms that offer scalability, flexibility and agility. In this context, the Data Lakes have gained popularity. But not all data lakes are the same, and here's where Databricks it's changing the rules of the game.
From traditional Data Lakes to Databricks Lakehouse
A traditional data lake allows you to store large volumes of raw, structured and unstructured data, without the need to define a previous schema. However, this flexibility is often accompanied by challenges: poor performance in analytical queries, data duplication, lack of governance, and operational complexity.
Databricks offers an intermediate solution with its Lakehouse architecture, which combines the best of data lakes and data warehouses. How does he do it?
- Using Delta Lake, a transactional storage layer on open formats such as Parquet.
- Integrating batch processing and streaming from the same environment.
- Offering interoperability with BI and data science tools without replicating data.
Key Benefits of a Data Lake in Databricks
1. Uncompromising scalability and performance
Databricks takes advantage of distributed processing of Apache Spark and own optimizations such as Photon, a vectorized engine designed for high performance. This allows you to scale from terabytes to petabytes without degrading analytical queries.
2. Open format and data governance
Delta Lake offers ACID transactions, data versioning (Time Travel) and schema management. All this in open formats, which avoids vendor lock-in and allows for better integration with other platforms.
3. Unified pipeline for analytics and AI
One of Databricks's greatest strengths is allowing analysts, engineers, and data scientists to work on same database, without silos. This speeds up the data lifecycle: from ingestion to visualization or model training.
4. Optimization of operating costs
Unlike other proprietary solutions, in Databricks you can Separate storage from computation, automate cluster scaling and apply strategies such as Self-Terminate, which significantly reduces costs if properly managed.
Common Use Cases for a Data Lake with Databricks
- Customer 360: consolidation of disparate data sources to build a single view of the customer.
- Real-time fraud detection: analysis of streaming events with ML models.
- Financial Forecasting: training predictive models directly on the data lake without moving data.
- Operational reporting: SQL queries on large volumes of historical data.
Who does it make the most sense for?
- Organizations that already use Spark or need to scale complex ETL pipelines.
- Teams that work with ML/IA and need a collaborative and reproducible platform.
- Companies that have problems with governance or duplication of data between lake and warehouse.
Data lakes are no longer just cheap data containers. With Databricks, they become engines of innovation: open, governable, and ready for advanced analysis. The question is no longer whether you need a data lake, but if your data lake is ready for the next stage of analytical maturity.
Blog Enki