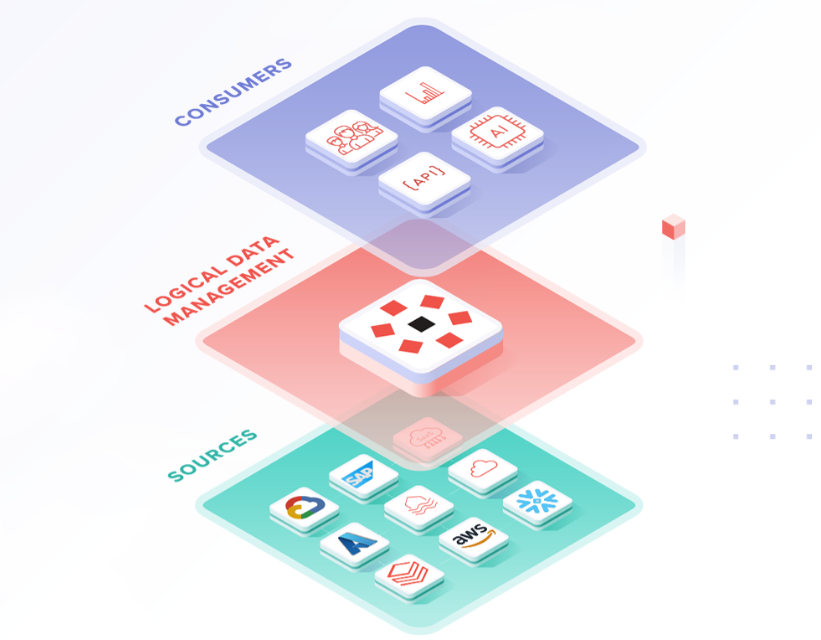
Los eTLs and the Data pipelines they are like a factory, but instead of making products, they process data. These data, coming from various sources (databases, files, applications), are the raw material that powers the systems of business intelligence.
What are they?
ETLs (Extract, Transform, Load) and data pipelines are fundamental concepts in the world of data processing and analysis. Although they share some similarities, they have distinctive features:
- ETL (Extract, Transform, Load): It is a process that involves extracting data from various sources, transforming it to adapt it to a specific format or performing calculations, and finally loading this data to a destination, usually a data warehouse or data warehouse.
- Data Pipeline: It is a set of processes and tools that automate the movement and transformation of data between a point of origin and a destination. Unlike ETLs, pipelines can handle data in real time and are more flexible in terms of the operations they can perform.
The importance of ETLs and Pipelines
In an increasingly data-driven world, ETLs and pipelines are critical for several reasons:
- Data quality: They ensure that data is clean, consistent, and reliable.
- Efficiency: They automate repetitive tasks, saving time and resources.
- Scalability: They adapt to growing volumes of data and to new sources of information.
- Agility: They allow us to respond quickly to changing business needs.
ETL process
The ETL process is divided into three main stages:
- Extraction (Extract): Data is obtained from a variety of sources, which may include databases, flat files, APIs, etc.
- Transform: The extracted data is cleaned, formatted and transformed according to business needs. This can include operations such as filtering, aggregation, normalization, and so on.
- Load: The transformed data is loaded into the target system, which is usually a data warehouse.
Pipelines Process
Data pipelines follow a more flexible flow and can include multiple stages:
- Data ingestion: Data capture from various sources, which can be in real time or in batches.
- Processing: Application of various transformations and analysis to the data entered.
- Storage: The processed data is stored in different destinations depending on the needs (databases, data lakes, etc.).
- Analysis and visualization: Many pipelines include stages for analyzing the processed data and generating visualizations or reports.
In today's big data and advanced analytics landscape, both ETLs and data pipelines play a crucial role in efficient information management. While ETLs are still essential for loading structured data into warehouses, pipelines offer greater flexibility to handle complex, real-time data flows. The choice between one or the other will depend on the specific needs of each organization, the type of data they handle and the analysis objectives they pursue. In many cases, a combination of both approaches can provide the most comprehensive and effective solution for data processing in modern business environments.
Blog Enki